Cloudy with Chances of Meatballs
-- It's raining FOOD
www.imdb.com/title/tt0844471/
X-Men Origins: Wolverine (2009)
After seeking to live a normal life, Logan sets out to avenge the death of his ...
www.imdb.com/title/tt0458525
Julie & Julia (2009)
"Julie & Julia" is based on the book by the same name, which is based on the true ... I enjoyed seeing the delicious meals both Julia and Julie prepared, ...
www.imdb.com/title/tt1135503/
The Princess and the Frog (2009)
A fairy tale set in Jazz Age-era New Orleans and centered on a young ...
www.imdb.com/title/tt0780521/
The Blind Side (2009)
-- Sandra Bullock, football
www.imdb.com/title/tt0878804/
Sunday, January 31, 2010
Friday, January 29, 2010
How to Install Adobe Flash Player 64-bit on Ubuntu 8.10
http://news.softpedia.com/news/How-to-Install-Adobe-Flash-Player-64-bit-on-Ubuntu-8-10-98076.shtml
eclipse system.out.println shortcut
http://www.java-forums.org/java-tips/3622-eclipse-shortcut-system-out-println.html
Code:
System.out.println();
This is a frequently used statement in Java. If you are working in Eclipse, you can save time using following shortcut:
type: syso
now presss CTRL + SPACE BAR
Enjoy coding.
Code:
System.out.println();
This is a frequently used statement in Java. If you are working in Eclipse, you can save time using following shortcut:
type: syso
now presss CTRL + SPACE BAR
Enjoy coding.
Wednesday, January 27, 2010
Stop Beagle in linux from eating your hard drive
http://beagle-project.org/FAQ#Can_I_disable_Beagle_and_stop_it_from_running.3F
Can I disable Beagle and stop it from running?
If Beagle is started automatically by your distribution, you can usually disable it for a given user by going to the "Search & Indexing" preferences in the control panel or by running the beagle-settings tool and unchecking the "Start search & indexing services automatically" box.
If you want to remove it for all users on the system, the best way is to remove the package from your system. On most distributions it is named beagle.
Can I disable Beagle and stop it from running?
If Beagle is started automatically by your distribution, you can usually disable it for a given user by going to the "Search & Indexing" preferences in the control panel or by running the beagle-settings tool and unchecking the "Start search & indexing services automatically" box.
If you want to remove it for all users on the system, the best way is to remove the package from your system. On most distributions it is named beagle.
set http proxy in console
export http_proxy=http://username:password@proxy.thing.com:8080/
If your web-access is censored by a http proxy, e.g. your web browser requires a http proxy, add the following lines to '~/.subversion/servers':
[groups]
mosuma=svn.mosuma.com
[mosuma]
http-proxy-host=proxy.ntu.edu.sg
http-proxy-port=8080
http://research.mosuma.com/faq/howto/svn_configure_proxy
If your web-access is censored by a http proxy, e.g. your web browser requires a http proxy, add the following lines to '~/.subversion/servers':
[groups]
mosuma=svn.mosuma.com
[mosuma]
http-proxy-host=proxy.ntu.edu.sg
http-proxy-port=8080
http://research.mosuma.com/faq/howto/svn_configure_proxy
Tuesday, January 26, 2010
Set Timex 1440 Sports watch
http://sudoit.blogspot.com/2008/11/set-timex-1440-sports-watch.html
Set Timex 1440 Sports watch
Couldn't find this anywhere on the web (the instruction manual for this watch does not match the watch). After many, many attempts I finally figured it out:
Press and hold the mode button for a few seconds, then, press the mode button again!
The 'set' button then changes the value while the 'start/stop' button will advance to the next thing to set.
Set the Timex 1440 Sports Watch (wr50m) Magnetism watch
hold down the "mode" button for 2 seconds. When the digits on the watch face start to blink, then press the "mode" button again. To change the hours, press the "adjust button". [instructions thanks to a comment below]
Posted by JTP at 7:56 PM
Labels: howto set 1440 Timex sports watch instructions
Set Timex 1440 Sports watch
Couldn't find this anywhere on the web (the instruction manual for this watch does not match the watch). After many, many attempts I finally figured it out:
Press and hold the mode button for a few seconds, then, press the mode button again!
The 'set' button then changes the value while the 'start/stop' button will advance to the next thing to set.
Set the Timex 1440 Sports Watch (wr50m) Magnetism watch
hold down the "mode" button for 2 seconds. When the digits on the watch face start to blink, then press the "mode" button again. To change the hours, press the "adjust button". [instructions thanks to a comment below]
Posted by JTP at 7:56 PM
Labels: howto set 1440 Timex sports watch instructions
Protein core, attachments, protein complex
http://www.ncbi.nlm.nih.gov/pubmed/18282471?log$=activity
Interaction networks for systems biology.
Bader S, Kühner S, Gavin AC.
EMBL, Structural and Computational Biology Unit, Meyerhofstrasse 1, D-69117 Heidelberg, Germany.
Cellular functions are almost always the result of the coordinated action of several proteins, interacting in protein complexes, pathways or networks. Progress made in devising suitable tools for analysis of protein-protein interactions, have recently made it possible to chart interaction networks on a large-scale. The aim of this review is to provide a short overview of the most promising contributions of interaction networks to human biology, structural biology and human genetics.
http://www.liebertonline.com/doi/abs/10.1089/cmb.2008.01TTJournal of Computational Biology
Predicting Protein Complexes from PPI Data: A Core-Attachment Approach
To cite this article:
Henry C.M. Leung, Qian Xiang, S.M. Yiu, Francis Y.L. Chin. Journal of Computational Biology. February 2009, 16(2): 133-144. doi:10.1089/cmb.2008.01TT.
http://string.embl.de/
STRING
Interaction networks for systems biology.
Bader S, Kühner S, Gavin AC.
EMBL, Structural and Computational Biology Unit, Meyerhofstrasse 1, D-69117 Heidelberg, Germany.
Cellular functions are almost always the result of the coordinated action of several proteins, interacting in protein complexes, pathways or networks. Progress made in devising suitable tools for analysis of protein-protein interactions, have recently made it possible to chart interaction networks on a large-scale. The aim of this review is to provide a short overview of the most promising contributions of interaction networks to human biology, structural biology and human genetics.
http://www.liebertonline.com/doi/abs/10.1089/cmb.2008.01TTJournal of Computational Biology
Predicting Protein Complexes from PPI Data: A Core-Attachment Approach
To cite this article:
Henry C.M. Leung, Qian Xiang, S.M. Yiu, Francis Y.L. Chin. Journal of Computational Biology. February 2009, 16(2): 133-144. doi:10.1089/cmb.2008.01TT.
http://string.embl.de/
STRING
Monday, January 25, 2010
Table of logic symbols
http://en.wikipedia.org/wiki/Table_of_logic_symbols
implies; if .. then
⇒
→
⊃
http://en.wikipedia.org/wiki/First-order_logic

Every propositional wff α can be converted into a formula α′ in
Conjunctive Normal Form (CNF) in such a way that |= α ≡ α′.
1. eliminate ⊃ and ≡ using (α ⊃ β) -> (¬α ∨ β) etc.
2. push ¬ inward using ¬(α ∧ β) -> (¬α ∨ ¬β) etc.
3. distribute ∨ over ∧ using ((α ∧ β) ∨ γ) -> ((α ∨ γ) ∧ (β ∨ γ))
4. collect terms using (α ∨ α) -> α etc.
http://en.wikipedia.org/wiki/Conjunctive_normal_form
http://www.enm.bris.ac.uk/ai/enjl/
http://www.enm.bris.ac.uk/ai/enjl/logic1.pdf
• 1. The connectives → and ↔ are eliminated using the equivalences
A ↔ B ≡ ( A → B) ∧ (B → A) and then A → B ≡ (¬ A∨ B)
• 2. Secondly, De Morgan’s Laws are applied as widely as possible
¬( A∧ B) is replaced by (¬ A∨ ¬ B)
¬( A∨ B) is replaced by (¬ A∧ ¬ B)
• 3. Multiple negations are reduced using DNEG e.g. ¬¬ A is replaced by A
• 4. The DISTOR rule is frequently applied
After the above procedures have been applied the original sentence is in conjunctive
normal form. Further simplifications can then be made by applying rule 1 (section 4) to
eliminate tautologies e.g. ((¬ A∨ A) ∧ B) ≡ B and repetitions within a clause can be
suppressed using IDOR e.g. A∨ A∨ A ≡ A. Also, if, in a normal form, a clause Ci is
included in another clause C j , the COR and AOR mean that the clausal brackets can be
removed e.g. (( A∨ B) ∨ D) ≡ ( A∨ B∨ D) ≡ ( A∨ ( B∨ D)) etc. Finally rule 1 can be used to
reduce a normal form containing a logically false clause to a logically false clause. Forms
simplified by the above procedures are said to be pure normal forms.
6. ≡ ((P ∧ ¬R) ∧ Q) ∨ (( ¬P ∨ R) ∨ ¬S)
7. ≡ (¬ ( ¬P ∨R ) ∧ Q ) ∨ ( (¬P ∨ R ) ∨ ¬S)8. ≡ ((¬( ¬P ∨ R ) ∧ Q ) ∨ (¬P ∨ R )) ∨ ¬S
9. ((¬ (¬P ∨ R ) ∧ Q) ∨ ( ¬P ∨ R)) ≡ ( Q ∨ ( ¬P ∨R ))
10. ((¬ (¬P ∨ R ) ∧ Q) ∨ ( ¬P ∨ R)) ∨ ¬S ≡ Q ∨¬P ∨ R ∨ ¬S
Skolemization
∃x∀yR(x,y) |= ∀y∃xR(x,y)
∀y∃xR(x,y) |≠ ∃x∀yR(x,y)
∃x∀y∃zP(x,y,z) to ∀yP(a,y,f(y))
Abbreviations:
(α ⊃ β) for (¬α ∨ β)
safer to read as disjunction than as “if ... then ...”
(α ≡ β) for ((α⊃β) ∧ (β⊃α))
implies; if .. then
⇒
→
⊃
http://en.wikipedia.org/wiki/First-order_logic

Every propositional wff α can be converted into a formula α′ in
Conjunctive Normal Form (CNF) in such a way that |= α ≡ α′.
1. eliminate ⊃ and ≡ using (α ⊃ β) -> (¬α ∨ β) etc.
2. push ¬ inward using ¬(α ∧ β) -> (¬α ∨ ¬β) etc.
3. distribute ∨ over ∧ using ((α ∧ β) ∨ γ) -> ((α ∨ γ) ∧ (β ∨ γ))
4. collect terms using (α ∨ α) -> α etc.
http://en.wikipedia.org/wiki/Conjunctive_normal_form
http://www.enm.bris.ac.uk/ai/enjl/
http://www.enm.bris.ac.uk/ai/enjl/logic1.pdf
• 1. The connectives → and ↔ are eliminated using the equivalences
A ↔ B ≡ ( A → B) ∧ (B → A) and then A → B ≡ (¬ A∨ B)
• 2. Secondly, De Morgan’s Laws are applied as widely as possible
¬( A∧ B) is replaced by (¬ A∨ ¬ B)
¬( A∨ B) is replaced by (¬ A∧ ¬ B)
• 3. Multiple negations are reduced using DNEG e.g. ¬¬ A is replaced by A
• 4. The DISTOR rule is frequently applied
After the above procedures have been applied the original sentence is in conjunctive
normal form. Further simplifications can then be made by applying rule 1 (section 4) to
eliminate tautologies e.g. ((¬ A∨ A) ∧ B) ≡ B and repetitions within a clause can be
suppressed using IDOR e.g. A∨ A∨ A ≡ A. Also, if, in a normal form, a clause Ci is
included in another clause C j , the COR and AOR mean that the clausal brackets can be
removed e.g. (( A∨ B) ∨ D) ≡ ( A∨ B∨ D) ≡ ( A∨ ( B∨ D)) etc. Finally rule 1 can be used to
reduce a normal form containing a logically false clause to a logically false clause. Forms
simplified by the above procedures are said to be pure normal forms.
6. ≡ ((P ∧ ¬R) ∧ Q) ∨ (( ¬P ∨ R) ∨ ¬S)
7. ≡ (¬ ( ¬P ∨R ) ∧ Q ) ∨ ( (¬P ∨ R ) ∨ ¬S)8. ≡ ((¬( ¬P ∨ R ) ∧ Q ) ∨ (¬P ∨ R )) ∨ ¬S
9. ((¬ (¬P ∨ R ) ∧ Q) ∨ ( ¬P ∨ R)) ≡ ( Q ∨ ( ¬P ∨R ))
10. ((¬ (¬P ∨ R ) ∧ Q) ∨ ( ¬P ∨ R)) ∨ ¬S ≡ Q ∨¬P ∨ R ∨ ¬S
Skolemization
∃x∀yR(x,y) |= ∀y∃xR(x,y)
∀y∃xR(x,y) |≠ ∃x∀yR(x,y)
∃x∀y∃zP(x,y,z) to ∀yP(a,y,f(y))
Abbreviations:
(α ⊃ β) for (¬α ∨ β)
safer to read as disjunction than as “if ... then ...”
(α ≡ β) for ((α⊃β) ∧ (β⊃α))
Movies
Ice Castles (1978) -- Robby Benson as Nick, Lynn-Holly Johnson as Alexis Winston
Theme Song: (Through the Eyes of Love) - Melissa Manchester
http://www.youtube.com/watch?v=WvP8u-9QX5s
Songwriter(s): Carole Bayer-Sager, Marvin Hamlisch
Please, don't let this feeling end
It's everything I am,
Everything I wanna be;
I can see what's mine now
Finding out what's true,
Since I've found you
Lookin' through the eyes of love.
Story about an ice skater who went blend, pretty good movie
http://www.imdb.com/title/tt0077716/
----
Up (2009)
Story about a widowed old man Mr. Carl Fredricksen, accompanied by an explorer kid, Russell as they transport their house over to Paradise Falls with lots and lots of balloons.
http://www.imdb.com/title/tt1049413/
Theme Song: (Through the Eyes of Love) - Melissa Manchester
http://www.youtube.com/watch?v=WvP8u-9QX5s
Songwriter(s): Carole Bayer-Sager, Marvin Hamlisch
Please, don't let this feeling end
It's everything I am,
Everything I wanna be;
I can see what's mine now
Finding out what's true,
Since I've found you
Lookin' through the eyes of love.
Story about an ice skater who went blend, pretty good movie
http://www.imdb.com/title/tt0077716/
----
Up (2009)
Story about a widowed old man Mr. Carl Fredricksen, accompanied by an explorer kid, Russell as they transport their house over to Paradise Falls with lots and lots of balloons.
http://www.imdb.com/title/tt1049413/
Wednesday, January 20, 2010
kr - resolution logic
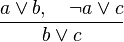
http://en.wikipedia.org/wiki/Resolution_(logic)
A simple example
\frac{a \vee b, \quad \neg a \vee c} {b \vee c}
In English: if a or b is true, and a is false or c is true, then either b or c is true.
If a is true, then for the second premise to hold, c must be true. If a is false, then for the first premise to hold, b must be true.
So regardless of a, if both premises hold, then b or c is true.
Claim: Resolvent is entailed by input clauses.
Suppose I |= (p ∨ α) and I |= (¬p ∨ β)
I |= p
Case 1:
then I | = β, so I |= (α ∨ β).
I |≠ p
Case 2:
then I | = α, so I | = (α ∨ β).
I | = (α ∨ β).
Either way,
{(p ∨ α), (¬p ∨ β)} |= (α ∨ β).
So:
ch4. informed search and explorartion
Heuristic search algorithms
----------------------------------------------------------
best first-search, uses evaluation function f(n) and heuristic function h(n) - estimated cost from n to the goal
Greedy best-first search f(n) = h(n), can go to infinite loop
A* search = f(n) = g(n) + h(n), optimal if h(n) is admissible ie h(n) <= h*(n)
consistent if h(n) <= c(n,a,n') + h(n')
h(G) = 0
e.g. shortest path from Arad to Bucharest, 8-puzzle sliding tile
A* (like breadth first) is complete and optimal, large space (keeps all nodes in memory) and time complexity, it needs to expand ALL fn <= C* (inside the contour) before expanding the next contour
trees don't loop (because childs are not connected with each other) (for A*, h(n) only needs to be admissible) but graphs can loop so graphs need to be more restrictive (for A*, it h(n) needs to be consistent), if h(n) is consistent then it's admissible but not the other way around ...
Local search and optimization / Iterative improvement algorithms - eg. n-queens
------------------------------------------------------------------------
local search algorithms (use when paths are irrelevant) operate a single current state (rather than multiple paths) and tries to improve it, generally move only to neighbours of that state, unsystematic, paths followed are not retained -> use less memory; also find solutions in large or infinite state spaces eg. nxn-queens problem, think of the state space landscape (hills), it doesn't matter how you got there, just that you got there.
hill-climbing search is like a greedy local search, it grabs a good neighbour state without thinking ahead about where to go next., fast but it gets stuck at local maxima sometimes, needs some restarting. gradient descent is like hill-climbing but it finds the minima. gradient descent is like a ping-pong ball falling down to a hole where the surface is bumpy.
simulated annealing is where you shake the surface a lot in the beginning (high temp) and then gradually reduce the intensity of shaking (lower temp.) over long period of time, so more bad moves are allowed at the beginning and as temperature T decreases, bad moves are less favoured. If T decreases slowly enough, the algorithm will find a global optimum approaching 1.
local beam search keeps track of k states rather than just one, starts off with k randomly generated states, at each step, all the successors of all k states are generated, if any one is a goal, the algorithm halts. Otherwise, it picks the k best successors from the complete list and repeats so useful information is passed among the k parallel search (not the case with a random-walk)
genetic algorithms is like a stochastic beam search in which successor states are generated by combining two parent states, rather than by modifying a single state, so it's like natural selection using sexual reproduction, operations include, 1) initial population 2) fitness function 3) selection 4) crossovers 5) mutations.
----------------------------------------------------------
best first-search, uses evaluation function f(n) and heuristic function h(n) - estimated cost from n to the goal
Greedy best-first search f(n) = h(n), can go to infinite loop
A* search = f(n) = g(n) + h(n), optimal if h(n) is admissible ie h(n) <= h*(n)
consistent if h(n) <= c(n,a,n') + h(n')
h(G) = 0
e.g. shortest path from Arad to Bucharest, 8-puzzle sliding tile
A* (like breadth first) is complete and optimal, large space (keeps all nodes in memory) and time complexity, it needs to expand ALL fn <= C* (inside the contour) before expanding the next contour
trees don't loop (because childs are not connected with each other) (for A*, h(n) only needs to be admissible) but graphs can loop so graphs need to be more restrictive (for A*, it h(n) needs to be consistent), if h(n) is consistent then it's admissible but not the other way around ...
Local search and optimization / Iterative improvement algorithms - eg. n-queens
------------------------------------------------------------------------
local search algorithms (use when paths are irrelevant) operate a single current state (rather than multiple paths) and tries to improve it, generally move only to neighbours of that state, unsystematic, paths followed are not retained -> use less memory; also find solutions in large or infinite state spaces eg. nxn-queens problem, think of the state space landscape (hills), it doesn't matter how you got there, just that you got there.
hill-climbing search is like a greedy local search, it grabs a good neighbour state without thinking ahead about where to go next., fast but it gets stuck at local maxima sometimes, needs some restarting. gradient descent is like hill-climbing but it finds the minima. gradient descent is like a ping-pong ball falling down to a hole where the surface is bumpy.
simulated annealing is where you shake the surface a lot in the beginning (high temp) and then gradually reduce the intensity of shaking (lower temp.) over long period of time, so more bad moves are allowed at the beginning and as temperature T decreases, bad moves are less favoured. If T decreases slowly enough, the algorithm will find a global optimum approaching 1.
local beam search keeps track of k states rather than just one, starts off with k randomly generated states, at each step, all the successors of all k states are generated, if any one is a goal, the algorithm halts. Otherwise, it picks the k best successors from the complete list and repeats so useful information is passed among the k parallel search (not the case with a random-walk)
genetic algorithms is like a stochastic beam search in which successor states are generated by combining two parent states, rather than by modifying a single state, so it's like natural selection using sexual reproduction, operations include, 1) initial population 2) fitness function 3) selection 4) crossovers 5) mutations.
Tuesday, January 19, 2010
Math Proofs
http://www.wikihow.com/Do-Math-Proofs
# Realize that a proof is just a good argument with every step justified. You can see about 50 proofs online [2].
# A good mathematical proof makes every step really obvious. Impressive-sounding statements might get marks in other subjects, but in mathematics they tend to hide holes in the reasoning.
http://www.physicsforums.com/showthread.php?t=166996
http://zimmer.csufresno.edu/~larryc/proofs/proofs.html
# Realize that a proof is just a good argument with every step justified. You can see about 50 proofs online [2].
# A good mathematical proof makes every step really obvious. Impressive-sounding statements might get marks in other subjects, but in mathematics they tend to hide holes in the reasoning.
http://www.physicsforums.com/showthread.php?t=166996
http://zimmer.csufresno.edu/~larryc/proofs/proofs.html
Monday, January 18, 2010
粉雪 - Konayuki - Powdered Snow
http://wiki.d-addicts.com/Konayuki
Konayuki
* Title: 粉雪
* Title (Romaji): Konayuki
* Title (English): Powdered Snow
* Lyrics/Music: Fujimaki Ryota
* Vocal: Remioromen
* Related TV Show: Ichi Rittoru no Namida (1 Litre of Tears)
Konayuki
* Title: 粉雪
* Title (Romaji): Konayuki
* Title (English): Powdered Snow
* Lyrics/Music: Fujimaki Ryota
* Vocal: Remioromen
* Related TV Show: Ichi Rittoru no Namida (1 Litre of Tears)
Sunday, January 17, 2010
seed physiology - control of seed development / maturation
A “switch” is needed to terminate development and promote the transition
to a germination and growth program
Important role of seed environment: To maintain embryos in a developmental
mode until they are fully formed and have accumulated sufficient reserves to
permit successful germination and subsequent seedling establishment
Two key regulatory factors are:
- restricted water uptake via negative osmosis (water encourage germination)
- abscisic acid (ABA) (encourage seed development/maturation/reserve synthesis)
Evidence for role of ABA:
1. embryo culture
2. mutants exhibiting vivipary (premature/precocious germination)
3. preharvest sprouting cereals
Response mutants:
- abi3 in arabidopsis (mustard)
- vp1 (abi3 homolog) in maize
to a germination and growth program
Important role of seed environment: To maintain embryos in a developmental
mode until they are fully formed and have accumulated sufficient reserves to
permit successful germination and subsequent seedling establishment
Two key regulatory factors are:
- restricted water uptake via negative osmosis (water encourage germination)
- abscisic acid (ABA) (encourage seed development/maturation/reserve synthesis)
Evidence for role of ABA:
1. embryo culture
2. mutants exhibiting vivipary (premature/precocious germination)
3. preharvest sprouting cereals
Response mutants:
- abi3 in arabidopsis (mustard)
- vp1 (abi3 homolog) in maize
seed physiology - dessication / mature drying
- seed looses h2o
- seed looses connection from parent plant
- metabolism stops
orthodox (traditional) vs recalcitrant seeds
orthodox eg. date palm
- looses 95% water
- store at dry and low temp.
recalcitrant eg. avocado, mango, lychee
- tropical seeds
- can't loose too much h2o
- doesn't go through maturation drying
- cannot be stored for long periods
coffee is intermediate, can survive seed dessication but dies in dry and low temp.
major mechanisms in seed dessication tolerance
1. carbohydrates - prevents large scale phase transition from liquid crystalline to dry gel by inserting sugar (e.g. raffinose) OH groups to phospholipid polar head groups
2. lipid-soluble antioxidants eg. glutathione, ascorbic acid, prevents peroxidation damage to lipid membranes due to free radicals and free fatty acid accumulation by scavenging for them
3. LEA (Late Embryogenesis Abundant) and LEAII - dehydrins (denaturation resistant proteins)
- 5 groups
- 1. random coil - able to conform to structures they contact, many OH groups to solvate cystolic structures and prevent their crystallization
- 2. amphipathic alpha-helix - hydrophobic (interacts with lipid membrane) and hydrophilic side (h bonds with polar groups of macromolecules) preventing coagulation
- 3. eleven amino acid motif - helix forming bundles (dimer) - hydrophobic (binds membranes) and hydrophilic sides (binds extra ions resulted from drying), > 1.5mM ion scavenging ability
counteracts increasing ionic strength buildup in cytosols
4. repair proteins:
- molecular chaperones - helps in protein folding
- ubiquitin - degrades damaged proteins
5. reserves help maintain mechanical strength to the whole cell
- seed looses connection from parent plant
- metabolism stops
orthodox (traditional) vs recalcitrant seeds
orthodox eg. date palm
- looses 95% water
- store at dry and low temp.
recalcitrant eg. avocado, mango, lychee
- tropical seeds
- can't loose too much h2o
- doesn't go through maturation drying
- cannot be stored for long periods
coffee is intermediate, can survive seed dessication but dies in dry and low temp.
major mechanisms in seed dessication tolerance
1. carbohydrates - prevents large scale phase transition from liquid crystalline to dry gel by inserting sugar (e.g. raffinose) OH groups to phospholipid polar head groups
2. lipid-soluble antioxidants eg. glutathione, ascorbic acid, prevents peroxidation damage to lipid membranes due to free radicals and free fatty acid accumulation by scavenging for them
3. LEA (Late Embryogenesis Abundant) and LEAII - dehydrins (denaturation resistant proteins)
- 5 groups
- 1. random coil - able to conform to structures they contact, many OH groups to solvate cystolic structures and prevent their crystallization
- 2. amphipathic alpha-helix - hydrophobic (interacts with lipid membrane) and hydrophilic side (h bonds with polar groups of macromolecules) preventing coagulation
- 3. eleven amino acid motif - helix forming bundles (dimer) - hydrophobic (binds membranes) and hydrophilic sides (binds extra ions resulted from drying), > 1.5mM ion scavenging ability
counteracts increasing ionic strength buildup in cytosols
4. repair proteins:
- molecular chaperones - helps in protein folding
- ubiquitin - degrades damaged proteins
5. reserves help maintain mechanical strength to the whole cell
seed physiology - reserve synthesis and deposition
protein, carbohydrates, oil
endosperm and cotyledons store mostly carbs and proteins, oil found in canola, pine
sucrose transfers from parent to seed via phloem
--------- PROTEINS eg. legumes ------------
Classification of seed storage proteins
Protein Type Solubility Characterisitic
Albumins 2S Water or dilute buffers at neutral pH
Globulins 7S Vicilins Salt solutions
11S Legumins / Glycinin?
12s Glycinin
Prolamins Aqueous alcohols (70-90%)
Glutelins Dilute acid or alkaline solutions

5'upstream - promoters, transcription control, enhancers
5'utr - indicate translation, untranslated region
coding region - exon/intron
3'utr - poly-A tail, stability
storage protein in peas - **vicilin, convicilin, *legumin, albumin
legumins - hexamer, 40 and 20kda
analyzing expression
dna (genomic southern blot), mrna (northern blot), protein and protein post-processing (western blot)
synthesis and processing of soybean glycinin

1. transcription in nucleus
2. translation of mrna in cytosol (cytoplasm matrix)
3. synthesis in the ER (preprolegumin - has signal),
4. then signal is cleaved (prolegumin) forms disulfide bond to form trimer
5. transport from golgi to protein body (e.g. vacuole - needs vacuolar targeting signals) to become hexamer (holoprotein) to become legumin
6. proteolytic cleave of proteins happen in vacuoles
parenchyma cells of cotyledons gets packed with protein bodies/protein storage vacuoles (PSV) (needs vacuolar targeting signals) (in dicots - storage is in vacuoles, in cereals - storage in rough ER)
default pathway is secretion, unless there's a vacuolar targeting signal, then it goes to vacuoles
3 types of targeting signals: continuous at N or C termini, discontinous signal patches, non-specific aggregation
--------- OILS eg, canola ------------
TAG(triacylglycerols) comprise the storage lipids of seeds (eg. canola, castor bean) and are accumulated in the oil body interior
oil bodies - half-unit membrane (one layer) that buds off from ER membrane bilayer
roles of oleosin:
1. maintain integrity of oil bodies during seed dessication (drying)
2. docking site for lipases that breaks down TAGs
central domain is highly conserved and important for targeting the protein to oil body membrane
---------- STARCH eg. maize/corn ------------
3 major enzymes in starch synthesis
1. ADP glucose pyrophosphorylase (ADPGlcPPase) - forms ADP-glucose
2. Starch synthase (SS) - connects ADP-glucose to the long alpha-1,4-glucan primer
3. Starch branching E (SBE) - moves alpha-1,4-glucan to another one via alpha-1,6 linkage
endosperm and cotyledons store mostly carbs and proteins, oil found in canola, pine
sucrose transfers from parent to seed via phloem
--------- PROTEINS eg. legumes ------------
Classification of seed storage proteins
Protein Type Solubility Characterisitic
Albumins 2S Water or dilute buffers at neutral pH
Globulins 7S Vicilins Salt solutions
11S Legumins / Glycinin?
12s Glycinin
Prolamins Aqueous alcohols (70-90%)
Glutelins Dilute acid or alkaline solutions

5'upstream - promoters, transcription control, enhancers
5'utr - indicate translation, untranslated region
coding region - exon/intron
3'utr - poly-A tail, stability
storage protein in peas - **vicilin, convicilin, *legumin, albumin
legumins - hexamer, 40 and 20kda
analyzing expression
dna (genomic southern blot), mrna (northern blot), protein and protein post-processing (western blot)
synthesis and processing of soybean glycinin

1. transcription in nucleus
2. translation of mrna in cytosol (cytoplasm matrix)
3. synthesis in the ER (preprolegumin - has signal),
4. then signal is cleaved (prolegumin) forms disulfide bond to form trimer
5. transport from golgi to protein body (e.g. vacuole - needs vacuolar targeting signals) to become hexamer (holoprotein) to become legumin
6. proteolytic cleave of proteins happen in vacuoles
parenchyma cells of cotyledons gets packed with protein bodies/protein storage vacuoles (PSV) (needs vacuolar targeting signals) (in dicots - storage is in vacuoles, in cereals - storage in rough ER)
default pathway is secretion, unless there's a vacuolar targeting signal, then it goes to vacuoles
3 types of targeting signals: continuous at N or C termini, discontinous signal patches, non-specific aggregation
--------- OILS eg, canola ------------
TAG(triacylglycerols) comprise the storage lipids of seeds (eg. canola, castor bean) and are accumulated in the oil body interior
oil bodies - half-unit membrane (one layer) that buds off from ER membrane bilayer
roles of oleosin:
1. maintain integrity of oil bodies during seed dessication (drying)
2. docking site for lipases that breaks down TAGs
central domain is highly conserved and important for targeting the protein to oil body membrane
---------- STARCH eg. maize/corn ------------
3 major enzymes in starch synthesis
1. ADP glucose pyrophosphorylase (ADPGlcPPase) - forms ADP-glucose
2. Starch synthase (SS) - connects ADP-glucose to the long alpha-1,4-glucan primer
3. Starch branching E (SBE) - moves alpha-1,4-glucan to another one via alpha-1,6 linkage
embryo development

1. globular
2. heart
3. torpedo
4. mature embryo
parts of mature seed
1. radicle (root)
2. seed coat (testa)
3. food reserve organs (endosperm - cereal/monocot, cotyledons - legumes/dicot, megagametophyte (1n) no endosperm - conifer/gymnosperm)
seed is a model of longevity
key processes that occur during seed maturation that impact on seed longevity and vigor:
a) accumulation and mobilization of food reserves - allows the seed to survive before it commences photosynthesis
b) hardening of the protective layers of the seed (seed coat, testa) - for mechanical support, interactions with wind, insects, prevents loss by leaching or absorptions of substances (water, solutes)
c) mechanisms for dispersal - seed flyers
d) intracellular synthesis of protective compounds - resistance to pathogens, antimicrobial, prevent water loss, antioxidant (prevent radical-mediated damage to membranes)
e) development of dormancy in species - Refers to the ability of dispersed seed to delay germination until the environmental conditions are appropriate for survival of the seedling, expression of genes that prevent germination and growth, broken by signals (cold/moist)
Saturday, January 16, 2010
Opportunities at the Intersection of Bioinformatics and Health Informatics A Case Study Perry L. Miller, MD, PhD
Opportunities at the Intersection of Bioinformatics and Health Informatics
A Case Study
Perry L. Miller, MD, PhD
This paper provides a “viewpoint discussion” based on a presentation made to the 2000 Symposium of the American College of Medical Informatics. It discusses potential opportunities for researchers in health informatics to become involved in the rapidly growing field of bioinformatics, using the activities of the Yale Center for Medical Informatics as a case study. One set of opportunities occurs where bioinformatics research itself intersects with the clinical world.
...
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC79037/
Evolving research trends in bioinformatics
Carolina Perez-Iratxeta, Miguel A. Andrade-Navarro and Jonathan D. Wren
Corresponding author. Jonathan D. Wren, PhD, The University of Oklahoma, 101 David L. Boren Blvd., Rm. 2025, Norman, OK 73019, USA. Tel: +1-405-325-3415; Fax: +1-405-325-3442; E-mail: Jonathan.Wren@OU.edu
http://bib.oxfordjournals.org/cgi/content/full/8/2/88
http://bib.oxfordjournals.org/current.dtl#PAPERS
http://bib.oxfordjournals.org/cgi/content/full/10/6/593
A Case Study
Perry L. Miller, MD, PhD
This paper provides a “viewpoint discussion” based on a presentation made to the 2000 Symposium of the American College of Medical Informatics. It discusses potential opportunities for researchers in health informatics to become involved in the rapidly growing field of bioinformatics, using the activities of the Yale Center for Medical Informatics as a case study. One set of opportunities occurs where bioinformatics research itself intersects with the clinical world.
...
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC79037/
Evolving research trends in bioinformatics
Carolina Perez-Iratxeta, Miguel A. Andrade-Navarro and Jonathan D. Wren
Corresponding author. Jonathan D. Wren, PhD, The University of Oklahoma, 101 David L. Boren Blvd., Rm. 2025, Norman, OK 73019, USA. Tel: +1-405-325-3415; Fax: +1-405-325-3442; E-mail: Jonathan.Wren@OU.edu
http://bib.oxfordjournals.org/cgi/content/full/8/2/88
http://bib.oxfordjournals.org/current.dtl#PAPERS
http://bib.oxfordjournals.org/cgi/content/full/10/6/593
Friday, January 15, 2010
Grad School Advice
http://web.pdx.edu/~obrienk/gradschool%20advice.pdf
http://www.howigotintostanford.com/shorter.php
http://www.justcolleges.com/grad/why-graduate-school.htm
http://www.military.com/finding-a-school/why-graduate-school
http://genomemedicine.com/content
http://www.biomedcentral.com/bmcbioinformatics?page=2&relevant=true
One of the great challenges of plant research is protecting crops from pathogenic attack. Soderlund describes a range of large-scale experimental studies for the analysis of plant–pathogen interactions, describing the bioinformatics approaches and tools that have been influential in gaining new knowledge from these data sets. She distinguishes between those problems that may be solved using generic bioinformatics methodologies and those for which bespoke solutions are required. Soderlund discusses key resources including fungal and oomycete databases and initiatives such as the PAMGO ontology, emphasizing the role of improved web-based resources in the knowledge discovery process.
Next, we shift our focus towards the important theme of understanding the genetic basis of plant traits. Zhang et al. describe methodologies for inferring genotype–phenotype associations through whole genome studies, focusing on the use of mixed model. The authors show that although many parts of the analytical process are rooted in animal studies and while some transfer directly to plant studies, others do not and need to be adapted. They discuss challenges to software engineering of the various methodologies involved, particularly in light of new high-throughput marker data sets, and discuss a number of software tools with regard to many key user requirements.
Finally, Lysenko et al. describe a problem that has arisen due to our capability to develop the data sets such as those described throughout this issue, that of developing software systems to integrate across information resources. The authors describe some of the problems inherent to data integration and discuss and contrast methods which are being used to solve them, while also noting the benefits of such approaches in generating new knowledge. They discuss two distinct, plant-oriented data integration case studies in the model plant Arabidopsis thaliana with reference to their own Ondex system, and look to new challenges in the form of high-throughput data sets, standards and ontologies.
http://bib.oxfordjournals.org/cgi/content/full/10/6/593
Disease to gene
http://bib.oxfordjournals.org.proxy.lib.sfu.ca/cgi/content/full/10/6/654
The Fungal Genome Initiative (FGI) [3] was formed to sequence fungal genomes,
Therefore, various software packages have been developed to partition the ESTs based on their nucleotide composition. Huitema et al. [35] used the fact that the GC content can sometimes be quite different between the host and pathogen. Maor et al. [36] developed the PF-IND method that uses codon usage bias. The problem with using codon usage is the need to find the in-frame coding sequence, and the fact that ESTs are also composed of untranslated regions. Therefore, Emmersen et al. [37] used triplet frequencies which are computed over both the coding and non-coding regions. The triplet frequencies are calculated using a sliding window over a training set of plant and pathogen ESTs, and a SVM (support vector machine) is used for the classifications.
http://www.howigotintostanford.com/shorter.php
http://www.justcolleges.com/grad/why-graduate-school.htm
http://www.military.com/finding-a-school/why-graduate-school
http://genomemedicine.com/content
http://www.biomedcentral.com/bmcbioinformatics?page=2&relevant=true
One of the great challenges of plant research is protecting crops from pathogenic attack. Soderlund describes a range of large-scale experimental studies for the analysis of plant–pathogen interactions, describing the bioinformatics approaches and tools that have been influential in gaining new knowledge from these data sets. She distinguishes between those problems that may be solved using generic bioinformatics methodologies and those for which bespoke solutions are required. Soderlund discusses key resources including fungal and oomycete databases and initiatives such as the PAMGO ontology, emphasizing the role of improved web-based resources in the knowledge discovery process.
Next, we shift our focus towards the important theme of understanding the genetic basis of plant traits. Zhang et al. describe methodologies for inferring genotype–phenotype associations through whole genome studies, focusing on the use of mixed model. The authors show that although many parts of the analytical process are rooted in animal studies and while some transfer directly to plant studies, others do not and need to be adapted. They discuss challenges to software engineering of the various methodologies involved, particularly in light of new high-throughput marker data sets, and discuss a number of software tools with regard to many key user requirements.
Finally, Lysenko et al. describe a problem that has arisen due to our capability to develop the data sets such as those described throughout this issue, that of developing software systems to integrate across information resources. The authors describe some of the problems inherent to data integration and discuss and contrast methods which are being used to solve them, while also noting the benefits of such approaches in generating new knowledge. They discuss two distinct, plant-oriented data integration case studies in the model plant Arabidopsis thaliana with reference to their own Ondex system, and look to new challenges in the form of high-throughput data sets, standards and ontologies.
http://bib.oxfordjournals.org/cgi/content/full/10/6/593
Disease to gene
http://bib.oxfordjournals.org.proxy.lib.sfu.ca/cgi/content/full/10/6/654
The Fungal Genome Initiative (FGI) [3] was formed to sequence fungal genomes,
Therefore, various software packages have been developed to partition the ESTs based on their nucleotide composition. Huitema et al. [35] used the fact that the GC content can sometimes be quite different between the host and pathogen. Maor et al. [36] developed the PF-IND method that uses codon usage bias. The problem with using codon usage is the need to find the in-frame coding sequence, and the fact that ESTs are also composed of untranslated regions. Therefore, Emmersen et al. [37] used triplet frequencies which are computed over both the coding and non-coding regions. The triplet frequencies are calculated using a sliding window over a training set of plant and pathogen ESTs, and a SVM (support vector machine) is used for the classifications.
AI - ch. 4 part 2
Annealing, in metallurgy and materials science, is a heat treatment wherein a material is altered, causing changes in its properties such as strength and hardness. It is a process that produces conditions by heating to above the re-crystallization temperature and maintaining a suitable temperature, and then cooling. Annealing is used to induce ductility, soften material, relieve internal stresses, refine the structure by making it homogeneous, and improve cold working properties.
In the cases of copper, steel, silver, and brass this process is performed by substantially heating the material (generally until glowing) for a while and allowing it to cool slowly. In this fashion the metal is softened and prepared for further work such as shaping, stamping, or forming.
Simulated annealing - I guess that explains why the algorithm is called like down, sometimes you gotta give to get something.
In the cases of copper, steel, silver, and brass this process is performed by substantially heating the material (generally until glowing) for a while and allowing it to cool slowly. In this fashion the metal is softened and prepared for further work such as shaping, stamping, or forming.
Simulated annealing - I guess that explains why the algorithm is called like down, sometimes you gotta give to get something.
Thursday, January 14, 2010
FoxitReader -- PDF Reader
http://www.foxitsoftware.com/downloads/index.php
They even have one for Linux
They even have one for Linux
Linux LPR print command
http://www.cups.org/documentation.php/options.html
Printing On Both Sides of the Paper
The -o sides=two-sided-short-edge and -o sides=two-sided-long-edge options will enable two-sided printing on the printer if the printer supports it. The -o sides=two-sided-short-edge option is suitable for landscape pages, while the -o sides=two-sided-long-edge option is suitable for portrait pages:
lp -o sides=two-sided-short-edge filename
lp -o sides=two-sided-long-edge filename
lpr -o sides=two-sided-long-edge filename
lpr -P MP560LAN -o InputSlot=Auto -o Resolution=600dpi -o PageSize=Letter
Printing On Both Sides of the Paper
The -o sides=two-sided-short-edge and -o sides=two-sided-long-edge options will enable two-sided printing on the printer if the printer supports it. The -o sides=two-sided-short-edge option is suitable for landscape pages, while the -o sides=two-sided-long-edge option is suitable for portrait pages:
lp -o sides=two-sided-short-edge filename
lp -o sides=two-sided-long-edge filename
lpr -o sides=two-sided-long-edge filename
lpr -P MP560LAN -o InputSlot=Auto -o Resolution=600dpi -o PageSize=Letter
Wednesday, January 13, 2010
Origami Bambi Deer
Bambi deer
http://go.squidoo.com/?id=1120X507259&url=http%3A%2F%2Fwww.origamiseiten.de%2Fforcher%2Fbambi.pdf
http://go.squidoo.com/?id=1120X507259&url=http%3A%2F%2Fwww.origamiseiten.de%2Fforcher%2Fbambi.pdf
Tuesday, January 12, 2010
PC Performance Measurement
http://en.wikibooks.org/wiki/Guide_to_Unix/Commands/System_Information
http://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
http://www.computerhope.com/unix/uuname.htm
http://www.bioinfo-user.org.uk/dokuwiki/doku.php/notes/unixsysteminformation
CPU info:
$ uname -X
$ psrinfo -v
$ dmesg
$ mount -v
$ prtconf -v http://www.computing.net/answers/solaris/solaris-machine-specification/3343.html
$ prstat # equiv. of top
http://www.cyberciti.biz/tips/top-linux-monitoring-tools.html
http://www.computerhope.com/unix/uuname.htm
http://www.bioinfo-user.org.uk/dokuwiki/doku.php/notes/unixsysteminformation
CPU info:
$ uname -X
$ psrinfo -v
$ dmesg
$ mount -v
$ prtconf -v http://www.computing.net/answers/solaris/solaris-machine-specification/3343.html
$ prstat # equiv. of top
Monday, January 11, 2010
seed physiology

angiosperm plant life-cycle
http://8e.devbio.com/image.php?id=525
Figure 4 Life cycle of an angiosperm, represented here by a pea plant (genus Pisum). The sporophyte is the dominant generation, but multicellular male and female gametophytes are produced within the flowers of the sporophyte. Cells of the microsporangium within the anther undergo meiosis to produce microspores. Subsequent mitotic divisions are limited, but the end result is a multicellular pollen grain. The megasporangium is protected by two layers of integuments and the ovary wall. Within the megasporangium, meiosis yields four megaspores—three small and one large. Only the large megaspore survives to produce the embryo sac. Fertilization occurs when the pollen germinates and the pollen tube grows toward the embryo sac. The sporophyte generation may be maintained in a dormant state, protected by the seed coat.
mitosis of microspores (1n) to microgametophyte / pollen grain (1n) yields
- vegetative cell (forms the pollen tube) (1n)
- generative cell 2 sperm (1n) cells
3 sets of mitosis (no cytokinesis) of megaspores (the only one that persists) (1n) to megagametophyte (2^3 = 8 in total)
- 3 antipodal cells (1n)
- 2 polar nuclei in the centre (each 1n)
- 2 synergid cells (1n) in egg aparatus
- 1 egg cell (1n) in egg aparatus
double fertilization (happens when pollen tube carrying 2 sperm cells reaches the egg aparatus):
- one sperm fuses with egg cells forming 2n zygote forming 2n embryo
- one sperm migrates from the synergid cell and fuses with the 2 polar nuclei forming 3n endosperm
key processes during seed maturation so seeds maintain vigor and longevity?
1. accumulation of food reserves
2. hardening of the seed coat (testa) (for structural support, interacts with wind, pathogens, prevent of loss by leaching) and accumulation of antimicrobial compounds
3. mechanisms of seed dispersal - flyers
4. synthesis of protective compounds that allow the seed to withstand some degree of water loss and adverse environmental conditions eg. antioxidants, antimicrobial, resistance to pathogens
5. dormancy - can happen for many years, needs signals or conditions to break the dormancy (eg. conifers at moist and low temperatures) or smoke
parts of the seed
1. embryonic root (radicle) and shoot
2. food reserve tissues or organs (cotyledons - legumes, endosperm - cereals and megagametophyte - pines)
3. seed coat (testa)

timing of events: stages of seed development
1. histodifferentiation - cell division
2. seed expansion (maturation) - genes for synthesis of reserves (proteins, lipids, carbohydrates) are expressed, deposition (depositing) of reserves
3 . maturation (drying) / dessication - water loss, embryo becomes quiescent state (metabolically inactive)
in situ - in place
gram-negative has lost the cell wall so does not retain the purple dye.
Most pathogenic bacteria in humans are gram-negative organisms. Classically, six gram-positive genera are typically pathogenic in humans. Two of these, Streptococcus and Staphylococcus, are cocci (coconut-shaped bacteria).
nutrients like sugar (sucrose) are transported to seed from parent plant via phloem, for peas, they are stored in the pods then later remobilized to the germinating seeds
classification of seed storage proteins:
- albumins - soluble in water
- globulins (7s vicilins and 11s legumins) - soluble in salt
- prolamins - soluble in alcohol
- glutelins - soluble in diulte acid and alkaline
ch 2 - the language of first-order logic
http://en.wikipedia.org/wiki/First-order_logic#Alphabet
Abbreviations:
(a \supset b) for (not a or b)
safer to read as disjunction than as “if ... then ...”
(a three-vertical-lines b) for (((a \supset b)) or ((b \supset a)))
well-formed formulas[3] or wffs
A is a subset of B and conversely B is a superset of A
* B is a proper superset of A; this is written as B\supsetneq A.
Abbreviations:
(a \supset b) for (not a or b)
safer to read as disjunction than as “if ... then ...”
(a three-vertical-lines b) for (((a \supset b)) or ((b \supset a)))
well-formed formulas[3] or wffs
A is a subset of B and conversely B is a superset of A
* B is a proper superset of A; this is written as B\supsetneq A.
ai - ch3 - solving problems by searching

search algorithms are judged on the basis of:
- completeness - find an answer if it exists
- optimality - find the best solution
- time complexity - # of nodes generated, BigO
- space complexity - # of nodes stored in memory
complexity depends on
- b - branching factor
- d - depth of the shallowest solution
- m - maximum depth of any path in the state space
Naive / blind search algorithms (b = branching factor, d = depth of solution, m = max depth of search tree, l = depth limit):
----------------------------------------------------------
- breadth-first search - can be memory intensive, time and space complexity O(b^d), complete and optimum
-- uniform-cost - breadth first but expands the lowest path cost first (greedy), same complexity as breadth-first
- depth-first search - not complete, not optimal, can take a long time, time complexity O(b^m), space complexity is good O(b*m) only -- only keeps node of a single path in memory
-- depth-limited search - has a limit l to the depth, but don't know limiting constant
- iterative deepening search - calls depth-limited with increasing limits, complete and optimal, same complexity as DFS
- bidirectional search, start from begininning and end until they meet halfway, O(b^(d/2))
informed search algorithms:
- best-first / greedy search
- A*
- local beam search - like breadth first search
consistent (triangle inequality): h(n) <= c(n, a, gn) + h(gn)
- n is starting node
- gn is the destination node, in this case, the goal node
- h(gn) = 0
- non-decreasing function
- c(n, a, gn) - cost of action a going from n to gn
- h(n) = cost from node n to goal
admissible - underestimating true (minimum) cost, so it never overestimates the cost
Sunday, January 10, 2010
Can't connect to Yaho using Pidgin
http://www.pidgin.im/download/ubuntu/
To setup the PPA, copy-and-paste these commands into a terminal:
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com \ 67265eb522bdd6b1c69e66ed7fb8bee0a1f196a8
echo deb http://ppa.launchpad.net/pidgin-developers/ppa/ubuntu \ `lsb_release --short --codename` main | \
sudo tee /etc/apt/sources.list.d/pidgin-ppa.list
sudo apt-get update
sudo apt-get install pidgin
To setup the PPA, copy-and-paste these commands into a terminal:
sudo apt-key adv --recv-keys --keyserver keyserver.ubuntu.com \ 67265eb522bdd6b1c69e66ed7fb8bee0a1f196a8
echo deb http://ppa.launchpad.net/pidgin-developers/ppa/ubuntu \ `lsb_release --short --codename` main | \
sudo tee /etc/apt/sources.list.d/pidgin-ppa.list
sudo apt-get update
sudo apt-get install pidgin
Can't play DVD in Ubuntu
http://www.videolan.org/vlc/download-ubuntu.html
% sudo apt-get update
% sudo apt-get install vlc vlc-plugin-esd mozilla-plugin-vlc libdvdcss2 libdvdcss
% sudo apt-get update
% sudo apt-get install vlc vlc-plugin-esd mozilla-plugin-vlc libdvdcss2 libdvdcss
Saturday, January 9, 2010
Wayne Williams's
http://en.wikipedia.org/wiki/Wayne_Williams
Wayne Williams's trial began on January 6, 1982. The prosecution's case relied on an abundance of circumstantial evidence. During the two-month trial, prosecutors matched 19 different sources of fibers from Williams's home and car environment: his bedspread, bathroom, gloves, clothes, carpets, his dog, and an unusual tri-lobal carpet fiber to a number of victims. There was also eyewitness testimony placing Williams with different victims, blood stains from victims matching blood in Williams's car, and testimony that he was a pedophile attracted to young black boys. Williams himself took the stand, but he seemingly alienated the jury by becoming angry and combative. Williams never recovered from that outburst, and on February 27, the jury deliberated for 12 hours before finding him guilty of murdering Cater and Payne. Williams was then sentenced by the Court to two consecutive terms of life imprisonment.[1]
Criminalistics, Saferstein 9th Ed.
http://wps.prenhall.com/chet_saferstein_criminalistics_9/
Important part to know is how probable it is to find the same fibre in a different place and what's the significance of this evidence?
it is the duty of the examiner as an impartial witness, to explain the evidence in terms of significance so that it will be clearly understood.
Wayne Williams's trial began on January 6, 1982. The prosecution's case relied on an abundance of circumstantial evidence. During the two-month trial, prosecutors matched 19 different sources of fibers from Williams's home and car environment: his bedspread, bathroom, gloves, clothes, carpets, his dog, and an unusual tri-lobal carpet fiber to a number of victims. There was also eyewitness testimony placing Williams with different victims, blood stains from victims matching blood in Williams's car, and testimony that he was a pedophile attracted to young black boys. Williams himself took the stand, but he seemingly alienated the jury by becoming angry and combative. Williams never recovered from that outburst, and on February 27, the jury deliberated for 12 hours before finding him guilty of murdering Cater and Payne. Williams was then sentenced by the Court to two consecutive terms of life imprisonment.[1]
Criminalistics, Saferstein 9th Ed.
http://wps.prenhall.com/chet_saferstein_criminalistics_9/
Important part to know is how probable it is to find the same fibre in a different place and what's the significance of this evidence?
it is the duty of the examiner as an impartial witness, to explain the evidence in terms of significance so that it will be clearly understood.
Grad School, Doing Research
http://gradschool.about.com/cs/shouldyougo/a/should.htm
Students choose graduate school for many reasons, including intellectual curiosity and professional advancement.
http://gradschool.about.com/od/essaywriting/a/questps.htm
Who am I?
Why do I want to continue my studies?
How can I address my academic record
How do field experiences enhance my application?
Who is my audience?
http://gradschool.about.com/od/essaywriting/a/DosandDonts.htm
# Discuss your future goals.
# Mention any hobbies, past jobs, community service, or research experience.
# Speak in the first person (I…).
# Mention weaknesses without making excuses.
# Discuss why you're interested in the school and/or program.
# Show, don’t tell (Use examples to demonstrate your abilities).
# Ask for help.
# Proofread and revise your statement at least 3 times.
# Have others proofread your essay.
http://gradschool.about.com/cs/essaywriting/a/essay1.htm
* Hobbies
* Projects that you've completed
* Jobs
* Responsibilities
* Accomplishments in the personal and scholastic arena
* Major life events that have changed you
* Challenges and hurdles you've overcome
* Life events that motivate your education
* People who have influenced you or motivated you
* Traits, work habits, and attitudes that will insure your success your goals
http://gradschool.about.com/od/essaywriting/a/whyessay.htm
Why the Admissions Essay?
Your essay is an indicator of your writing ability, motivation, ability to express yourself, maturity, passion for the field, and judgment. Admissions committees read essays with the intent to learn more about applicants, to determine if they have the qualities and attitudes needed for success, and to weed out applicants who don't fit the program.
However, your underlying theme should be why you should be accepted into graduate school or specifically accepted into the program to which you are applying. Your job is to sell yourself and distinguish yourself from other applicants through examples.
Should I write in the first person?
Although you were taught to avoid using I, we, my, etc., you are encouraged to speak in the first person on your personal statement. Your goal is to make your essay sound personal and active. However, avoid overusing “I” and, instead, alter between I and other first person terms, such as “my” and “me” and transition words, such as "however" and "therefore."
How should I discuss my research interests in my personal statement?
First, it is not necessary to state a specific and concise dissertation topic in your personal statement. You are only to state, in broad terms, your research interests within your field. The reason you are asked to discuss your research interests is because the program would like to compare the degree of similarity in research interests between you and the faculty member you wish to work with. Admissions committees are aware that your interests will likely change over time and, therefore, they do not expect you to provide them with a detailed description of your research interests but would like for you to describe your academic goals. However, your research interests should be relevant to the proposed field of study. Additionally, your aim is to show your readers that you have knowledge in your proposed field of study.
Here's what the admissions committee considers when reading an applicant's admissions essay:
* How well does the applicant address the assigned question?
* If no specific topic is assigned, how well does the applicant manage the ambiguous assignment and construct an essay that is relevant and informative?
* How well does the applicant write?
* Does the applicant attend to details, such as spelling and presentation?
* Does the essay illustrate critical thinking?
* Does the applicant demonstrate abstract and complex reasoning?
* Is the essay appropriate? Is it too informal?
* Does the applicant reveal appropriate personal details and avoid sharing irrelevant and overly personal information (e.g., mental illness, childhood experiences, family tragedies, etc.)?
* Is the essay free of careless errors (e.g., listing the wrong school)?
* How well is the essay organized? Is it easy to read and to follow the author's ideas?
http://gradschool.about.com/cs/miscellaneous/a/want.htm
What Do Graduate Schools Want?
The Ideal Grad Student
The ideal graduate student is gifted, eager to learn, and highly motivated. He or she can work independently and take direction, supervision, and constructive criticism without becoming upset or overly sensitive. Faculty look for students who are hard workers, want to work closely with faculty, are responsible and easy to work with, and who are a good fit to the program. The best graduate students complete the program on time, with distinction - and excel in the professional world to make graduate faculty proud. Of course, these are ideals. Most graduate students have some of these characteristics, but nearly no one will have all, so don't fear.
http://vmcl.xjtu.edu.cn/studyZone/writing/How_to_be_a_Good_Graduate_Student_Advisor/how.2b.research.html
The hardest part of getting a Ph.D. is, of course, writing the dissertation. The process of finding a thesis topic, doing the research, and writing the thesis is different from anything most students have done before. If you have a good advisor and support network, you'll be able to get advice and help in setting directions and goals.
Of course, the ideal advisor will be in the area you're interested in working in, and will actively be doing high-quality reseach and be involved in and respected by the research community.
A good advisor will serve as a mentor as well as a source of technical assistance. A mentor should provide, or help you to find, the resources you need (financial, equipment, and psychological support); introduce you and promote your work to important people in your field; encourage your own interests, rather than promoting their own; be available to give you advice on the direction of your thesis and your career; and help you to find a job when you finish. They should help you to set and achieve long-term and short-term goals.
The most important thing is to ask for (i.e., demand politely) what you need.
A good source of ideas for master's projects (and sometimes for dissertation topics) is the future work section of papers you're interested in. Try developing and implementing an extension to an existing system or technique.
In any case, a good topic will address important issues. You should be trying to solve a real problem, not a toy problem (or worse yet, no problem at all); you should have solid theoretical work, good empirical results or, preferably, both; and the topic will be connected to -- but not be a simple variation on or extension of -- existing research. It will also be significant yet manageable. Finding the right size problem can be difficult. One good way of identifying the right size is to read other dissertations. It's also useful to have what Chapman [chapman] calls a ``telescoping organization'' -- a central problem that's solvable and acceptable, with extensions and additions that are ``successively riskier and that will make the thesis more exciting.'' If the gee-whiz additions don't pan out, you'll still have a solid result.
In order to get feedback, you have to present your ideas. Write up what you're working on, even if you're not ready to write a full conference or journal paper, and show it to people. Even for pre-publishable papers, write carefully and clearly, to maximize your chances of getting useful comments (and of having people read what you wrote at all).
Give presentations at seminar series at your university, at conferences, and at other universities and research labs when you get the chance. Your advisor should help you find appropriate forums to present your work and ideas. Many fields have informal workshops that are ideal for presenting work in progress.
Students choose graduate school for many reasons, including intellectual curiosity and professional advancement.
http://gradschool.about.com/od/essaywriting/a/questps.htm
Who am I?
Why do I want to continue my studies?
How can I address my academic record
How do field experiences enhance my application?
Who is my audience?
http://gradschool.about.com/od/essaywriting/a/DosandDonts.htm
# Discuss your future goals.
# Mention any hobbies, past jobs, community service, or research experience.
# Speak in the first person (I…).
# Mention weaknesses without making excuses.
# Discuss why you're interested in the school and/or program.
# Show, don’t tell (Use examples to demonstrate your abilities).
# Ask for help.
# Proofread and revise your statement at least 3 times.
# Have others proofread your essay.
http://gradschool.about.com/cs/essaywriting/a/essay1.htm
* Hobbies
* Projects that you've completed
* Jobs
* Responsibilities
* Accomplishments in the personal and scholastic arena
* Major life events that have changed you
* Challenges and hurdles you've overcome
* Life events that motivate your education
* People who have influenced you or motivated you
* Traits, work habits, and attitudes that will insure your success your goals
http://gradschool.about.com/od/essaywriting/a/whyessay.htm
Why the Admissions Essay?
Your essay is an indicator of your writing ability, motivation, ability to express yourself, maturity, passion for the field, and judgment. Admissions committees read essays with the intent to learn more about applicants, to determine if they have the qualities and attitudes needed for success, and to weed out applicants who don't fit the program.
However, your underlying theme should be why you should be accepted into graduate school or specifically accepted into the program to which you are applying. Your job is to sell yourself and distinguish yourself from other applicants through examples.
Should I write in the first person?
Although you were taught to avoid using I, we, my, etc., you are encouraged to speak in the first person on your personal statement. Your goal is to make your essay sound personal and active. However, avoid overusing “I” and, instead, alter between I and other first person terms, such as “my” and “me” and transition words, such as "however" and "therefore."
How should I discuss my research interests in my personal statement?
First, it is not necessary to state a specific and concise dissertation topic in your personal statement. You are only to state, in broad terms, your research interests within your field. The reason you are asked to discuss your research interests is because the program would like to compare the degree of similarity in research interests between you and the faculty member you wish to work with. Admissions committees are aware that your interests will likely change over time and, therefore, they do not expect you to provide them with a detailed description of your research interests but would like for you to describe your academic goals. However, your research interests should be relevant to the proposed field of study. Additionally, your aim is to show your readers that you have knowledge in your proposed field of study.
Here's what the admissions committee considers when reading an applicant's admissions essay:
* How well does the applicant address the assigned question?
* If no specific topic is assigned, how well does the applicant manage the ambiguous assignment and construct an essay that is relevant and informative?
* How well does the applicant write?
* Does the applicant attend to details, such as spelling and presentation?
* Does the essay illustrate critical thinking?
* Does the applicant demonstrate abstract and complex reasoning?
* Is the essay appropriate? Is it too informal?
* Does the applicant reveal appropriate personal details and avoid sharing irrelevant and overly personal information (e.g., mental illness, childhood experiences, family tragedies, etc.)?
* Is the essay free of careless errors (e.g., listing the wrong school)?
* How well is the essay organized? Is it easy to read and to follow the author's ideas?
http://gradschool.about.com/cs/miscellaneous/a/want.htm
What Do Graduate Schools Want?
The Ideal Grad Student
The ideal graduate student is gifted, eager to learn, and highly motivated. He or she can work independently and take direction, supervision, and constructive criticism without becoming upset or overly sensitive. Faculty look for students who are hard workers, want to work closely with faculty, are responsible and easy to work with, and who are a good fit to the program. The best graduate students complete the program on time, with distinction - and excel in the professional world to make graduate faculty proud. Of course, these are ideals. Most graduate students have some of these characteristics, but nearly no one will have all, so don't fear.
http://vmcl.xjtu.edu.cn/studyZone/writing/How_to_be_a_Good_Graduate_Student_Advisor/how.2b.research.html
The hardest part of getting a Ph.D. is, of course, writing the dissertation. The process of finding a thesis topic, doing the research, and writing the thesis is different from anything most students have done before. If you have a good advisor and support network, you'll be able to get advice and help in setting directions and goals.
Of course, the ideal advisor will be in the area you're interested in working in, and will actively be doing high-quality reseach and be involved in and respected by the research community.
A good advisor will serve as a mentor as well as a source of technical assistance. A mentor should provide, or help you to find, the resources you need (financial, equipment, and psychological support); introduce you and promote your work to important people in your field; encourage your own interests, rather than promoting their own; be available to give you advice on the direction of your thesis and your career; and help you to find a job when you finish. They should help you to set and achieve long-term and short-term goals.
The most important thing is to ask for (i.e., demand politely) what you need.
A good source of ideas for master's projects (and sometimes for dissertation topics) is the future work section of papers you're interested in. Try developing and implementing an extension to an existing system or technique.
In any case, a good topic will address important issues. You should be trying to solve a real problem, not a toy problem (or worse yet, no problem at all); you should have solid theoretical work, good empirical results or, preferably, both; and the topic will be connected to -- but not be a simple variation on or extension of -- existing research. It will also be significant yet manageable. Finding the right size problem can be difficult. One good way of identifying the right size is to read other dissertations. It's also useful to have what Chapman [chapman] calls a ``telescoping organization'' -- a central problem that's solvable and acceptable, with extensions and additions that are ``successively riskier and that will make the thesis more exciting.'' If the gee-whiz additions don't pan out, you'll still have a solid result.
In order to get feedback, you have to present your ideas. Write up what you're working on, even if you're not ready to write a full conference or journal paper, and show it to people. Even for pre-publishable papers, write carefully and clearly, to maximize your chances of getting useful comments (and of having people read what you wrote at all).
Give presentations at seminar series at your university, at conferences, and at other universities and research labs when you get the chance. Your advisor should help you find appropriate forums to present your work and ideas. Many fields have informal workshops that are ideal for presenting work in progress.
Friday, January 8, 2010
BigO, Time Complexity
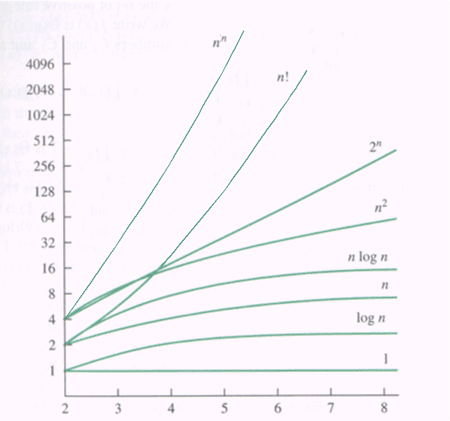
Time Complexity T(n)
http://planetmath.org/encyclopedia/TimeComplexity.html
- O(n2) and O(n3) are both polynomial time complexity classes, similarly O(2n) and O(3n) are exponential time complexity classes.
- All comparison-based sorting has time complexity no better than O(nlogn) , where n is the number of elements to be sorted.
http://www.topcoder.com/tc?module=Static&d1=tutorials&d2=complexity1
- How fast does the maximum runtime grow when we increase the input size?
- the worst possible case
- the input size is the length of the array/string, when talking about graph problems, the input size depends both on the number of vertices (N) and the number of edges (M), etc.
- worst of these inputs (i.e. theone that causes the algorithm to do the most steps).
E.g. if f (N) = $ \Theta$(N), we call the algorithm linear. More examples:
* f (N) = $ \Theta$(log N): logarithmic
* f (N) = $ \Theta$(N2): quadratic (bubble-sort)
* f (N) = $ \Theta$(N3): cubic multiply two nxn matrices
* f (N) = O(Nk) for some k: polynomial
* f (N) = $ \Omega$(2N): exponential
http://www.cs.odu.edu/~toida/nerzic/content/function/growth_files/summary.gif
For graph problems, the complexity $ \Theta$(N + M) is known as "linear in the graph size".
http://www.leda-tutorial.org/en/official/ch02s02s03.html
The number of (machine) instructions which a program executes during its running time is called its time complexity in computer science. This number depends primarily on the size of the program's input, that is approximately on the number of the strings to be sorted (and their length) and the algorithm used. So approximately, the time complexity of the program “sort an array of n strings by minimum search” is described by the expression c·n2.
http://en.wikipedia.org/wiki/Big_O_notation#Example_2
n=2^k, k = log2n
In typical usage, the formal definition of O notation is not used directly; rather, the O notation for a function f(x) is derived by the following simplification rules:
* If f(x) is a sum of several terms, the one with the largest growth rate is kept, and all others omitted.
* If f(x) is a product of several factors, any constants (terms in the product that do not depend on x) are omitted.
http://pages.pacificcoast.net/~cazelais/222/big-o.pdf
f(x) = (x2 + 5 log2 x)/(2x + 1) is O(x).
f(x) = (x + 5) log2(3x2 + 7) is O(x log2 x).
f(x) = 4x2 − 5x + 3 is O(x2).
kr - ch1, 2
http://users.skynet.be/bs661306/peter/doc/hpv00r03-841.htm
KR (Knowledge Representation) Hypothesis (Smith 1982):
1. there's some structural ingredients to represent knowledge -- knowledge base
2. there's some process to manipulate these ingredients via inference -- reasoning
Notes; Exist structures that:
• we can interpret propositionally
• determine how the system behaves
eg. Expert system, GPS
http://en.wikipedia.org/wiki/General_Problem_Solver
General Problem Solver (GPS) was a computer program created in 1957 by Herbert Simon, J.C. Shaw, and Allen Newell intended to work as a universal problem solver machine. Any formalized symbolic problem can be solved, in principle, by GPS. For instance: theorems proof, geometric problems and chess playing. It was based on Simon and Newell's theoretical work on logic machines. GPS was the first computer program which separated its knowledge of problems (rules represented as input data) from its strategy of how to solve problems (a generic solver engine).
reasoning - Manipulation of symbols encoding propositions to produce representations of new propositions
representation - symbols standing for things in the world
knowledge - taking the world to be one way and not the other, propositions, eg. I know that the sky is blue
entails - eg kb entails alpha, so if the world satisfies kb then it must also (implied that it) satisfy alpha
inference - process of calculating entailments
sound - get only entailments
complete - get all entailments
the language of first order logic
wffs - well-formed formula, St(Bob) V St(Sue) is wff but St(Bob V Sue) is not wff
abbrevations:
logical symbols:
(α ⊃ β) for (¬α ∨ β)
(α ≡ β) for ((α⊃β) ∧ (β⊃α))
x ⊃ y means x -> y means if x then y
non-logical symbols: predicates, functions
a sentence: wff with no free variables (closed)
Substitution: α[v/t] means α with all free occurrences of the v replaced by term t
free occurrence (no scope - ∃ and ∀)
interpretation - Each interpretation assigns to function f a mapping from objects to objects. ℑ = 〈 D, I 〉, D is the domain of discourse (eg people, table), I is an interpretation mapping (eg prop symbols -> true, false)
satisfaction
will write as ℑ,µ = α “α is satisfied by ℑ and µ”
where µ ∈ [Variables → D], as before
or ℑ = α, when α is a sentence
“α is true under interpretation ℑ”
or ℑ = S, when S is a set of sentences
Entailment defined
S |= α iff for every ℑ , if ℑ |= S then ℑ |= α.
Say that S entails α or α is a logical consequence of S:
In other words: for no ℑ , ℑ |= S ∪ {¬α}. S ∪ {¬α} is unsatisfiable
“the elements of S are true under interpretation ℑ”
S = KB = Knowledge base
Special case when S is empty: |= α iff for every ℑ , ℑ |= α.
Say that α is valid. (p.30)
***
include such connections explicitly in S
Key idea ∀x[Dog(x) ⊃ Mammal(x)]
of KR: the rest is just
Get: S ∪ {Dog(fido)} |= Mammal(fido) details...
p33. proof by interpretation, if S |= alpha then I |= S and I= alpha
case1. I |= Green(b), show I |= Green(b) ∧ ¬Green(c) ∧ On(b,c). (based on S, so entailed)
case2. I |= ~Green(b), show I |= Green(a) ∧ ¬Green(b) ∧ On(a,b). (based on S, so entailed)
if I |= alpha, then I is a model of alpha
eg. soap opera world - domains
individuals: john, sleezyTown
basic types: Place, Person
relationships / functions: MarriedTo, DaugherOf
facts = terms
Man(john)
Rich(john)
∀y[Woman(y) ∧ y ≠ jane ⊃ Loves(y,john)]
x ⊃ y means x -> y means if x then y
attributes: Rich, Beautiful
closure: ∀x[Person(x) ⊃ x=jane ∨ x=john ∨ x=jim ...]
Denotation p27
||t||i,u where u in [variables -> d]
Clausal representation p48
Formula = conjunction ^ of clauses { [p, r, s], [p, r, s], [ p ] }
Clause = disjunction V of literals [p, r, s]
Literal = atomic sentence or its negation p
positive literal and negative literal
Resolvent
clauses [w, r, q] and [w, s, ~r] have [w, q, s] as resolvent wrt r.
Resolution is refutation complete
Resolution p53. (uses the process of derivations)
To determine if KB |= a,
1. put KB, ~a into CNF to get S
2. if S->[], the KB V ~a is unsatisfiable and so KB |= a
3. otherwise, KB V ~a is satisfiable and so KB does not entail a
ground if literal contains NO variables eg. Wife(bob,marry)
Generalizing CNF p.57
Generalizing CNF
Resolution will generalize to handling variables
But to convert wffs to CNF, we need three additional steps:
1. eliminate É and º
2. push Ø inward using also Ø"x.a ß $x.Øa etc.
3. standardize variables: each quantifier gets its own variable
e.g. $x[P(x)] Ù Q(x) ß $z[P(z)] Ù Q(x) where z is a new variable
4. eliminate all existentials (discussed later)
5. move universals to the front using ("xa) Ù b ß "x(aÙ b)
where b does not use x
6. distribute Ú over Ù
7. collect terms
Get universally quantified conjunction of disjunction of literals
Answer predicate - A(x)
[~St(x), ~Happy(x), A(x)]
...
[A(bob)]
Skolem - names for individuals claimed to exist, called Skolem
Skolem preserve satisfiability, not equivalence so ExP(x) not equal P(a)!!
*MGU - most general unifier p70. / unification
- finding skolem variables theta given P(f(x), y, g(y)) and P(f(x), z, g(x)), answer is theta = {y/z, z/x} to get P(f(x), x, g(x))
***Note: important to get dependence of variables correct p65
AyExR(x,y) => AyR(f(y),y) so the best way to remember is to put brackets, it's better Ax (for all x) is inside the bracket because it's more flexible
vs. ExAyR(x,y) => AyR(a,y)
strategies:
- directional connectives (forward, backward)
- unit clauses
- set of support (always resolve with at least one clause that's the ancestor of ~q, just unifying with KB is useless)
- clause elimination, tautology (always true), pure clause (only one atom p in the formula)
horn clause = has at MOST one +ve literal (p80)
- as implications: (¬child ∨ ¬male ∨ boy)
- e.g. [¬p1, ¬p2, ..., ¬pn, q]
- e.g. [¬p1, ¬p2, ..., ¬pn] and also [ ] (all negative)
- p1 ∧ p2 ∧ ... ∧ pn ⇒ q (if p1 and p2 and ... and pn then q) or Note:
(¬p1 ∨ ¬p2 ∨ ... ∨ ¬pn ∨ q) or [(p1 ∧ p2 ∧ ... ∧ pn) ⊃ q]
SLD - (Selected literals) (linear form) (definite clauses)
sld derivation / resolution in Horn clauses - can also use a goal tree where the root is the goal and leaves are in the KB
back-chaining - depth first, left-right, back-chaining (strategy used in Prolog), can go to inf. loop
forward-chaining - mark atoms as solved
problem - can give inf. branch of resolvents in FOL
Standardize variables: each quantifier should use a different one
Ordering goals p94.
1. get ParentOf(sam,z): find child of Sam searching downwards
2. get ParentOf(z,sue): find parent of Sue searching upwards
3. get ParentOf(–,–): find parent relations searching in both directions
Search strategies are not equivalent
if more than 2 children per parent, (2) is best
KR (Knowledge Representation) Hypothesis (Smith 1982):
1. there's some structural ingredients to represent knowledge -- knowledge base
2. there's some process to manipulate these ingredients via inference -- reasoning
Notes; Exist structures that:
• we can interpret propositionally
• determine how the system behaves
eg. Expert system, GPS
http://en.wikipedia.org/wiki/General_Problem_Solver
General Problem Solver (GPS) was a computer program created in 1957 by Herbert Simon, J.C. Shaw, and Allen Newell intended to work as a universal problem solver machine. Any formalized symbolic problem can be solved, in principle, by GPS. For instance: theorems proof, geometric problems and chess playing. It was based on Simon and Newell's theoretical work on logic machines. GPS was the first computer program which separated its knowledge of problems (rules represented as input data) from its strategy of how to solve problems (a generic solver engine).
reasoning - Manipulation of symbols encoding propositions to produce representations of new propositions
representation - symbols standing for things in the world
knowledge - taking the world to be one way and not the other, propositions, eg. I know that the sky is blue
entails - eg kb entails alpha, so if the world satisfies kb then it must also (implied that it) satisfy alpha
inference - process of calculating entailments
sound - get only entailments
complete - get all entailments
the language of first order logic
wffs - well-formed formula, St(Bob) V St(Sue) is wff but St(Bob V Sue) is not wff
abbrevations:
logical symbols:
(α ⊃ β) for (¬α ∨ β)
(α ≡ β) for ((α⊃β) ∧ (β⊃α))
x ⊃ y means x -> y means if x then y
non-logical symbols: predicates, functions
a sentence: wff with no free variables (closed)
Substitution: α[v/t] means α with all free occurrences of the v replaced by term t
free occurrence (no scope - ∃ and ∀)
interpretation - Each interpretation assigns to function f a mapping from objects to objects. ℑ = 〈 D, I 〉, D is the domain of discourse (eg people, table), I is an interpretation mapping (eg prop symbols -> true, false)
satisfaction
will write as ℑ,µ = α “α is satisfied by ℑ and µ”
where µ ∈ [Variables → D], as before
or ℑ = α, when α is a sentence
“α is true under interpretation ℑ”
or ℑ = S, when S is a set of sentences
Entailment defined
S |= α iff for every ℑ , if ℑ |= S then ℑ |= α.
Say that S entails α or α is a logical consequence of S:
In other words: for no ℑ , ℑ |= S ∪ {¬α}. S ∪ {¬α} is unsatisfiable
“the elements of S are true under interpretation ℑ”
S = KB = Knowledge base
Special case when S is empty: |= α iff for every ℑ , ℑ |= α.
Say that α is valid. (p.30)
***
include such connections explicitly in S
Key idea ∀x[Dog(x) ⊃ Mammal(x)]
of KR: the rest is just
Get: S ∪ {Dog(fido)} |= Mammal(fido) details...
p33. proof by interpretation, if S |= alpha then I |= S and I= alpha
case1. I |= Green(b), show I |= Green(b) ∧ ¬Green(c) ∧ On(b,c). (based on S, so entailed)
case2. I |= ~Green(b), show I |= Green(a) ∧ ¬Green(b) ∧ On(a,b). (based on S, so entailed)
if I |= alpha, then I is a model of alpha
eg. soap opera world - domains
individuals: john, sleezyTown
basic types: Place, Person
relationships / functions: MarriedTo, DaugherOf
facts = terms
Man(john)
Rich(john)
∀y[Woman(y) ∧ y ≠ jane ⊃ Loves(y,john)]
x ⊃ y means x -> y means if x then y
attributes: Rich, Beautiful
closure: ∀x[Person(x) ⊃ x=jane ∨ x=john ∨ x=jim ...]
Denotation p27
||t||i,u where u in [variables -> d]
Clausal representation p48
Formula = conjunction ^ of clauses { [p, r, s], [p, r, s], [ p ] }
Clause = disjunction V of literals [p, r, s]
Literal = atomic sentence or its negation p
positive literal and negative literal
Resolvent
clauses [w, r, q] and [w, s, ~r] have [w, q, s] as resolvent wrt r.
Resolution is refutation complete
Resolution p53. (uses the process of derivations)
To determine if KB |= a,
1. put KB, ~a into CNF to get S
2. if S->[], the KB V ~a is unsatisfiable and so KB |= a
3. otherwise, KB V ~a is satisfiable and so KB does not entail a
ground if literal contains NO variables eg. Wife(bob,marry)
Generalizing CNF p.57
Generalizing CNF
Resolution will generalize to handling variables
But to convert wffs to CNF, we need three additional steps:
1. eliminate É and º
2. push Ø inward using also Ø"x.a ß $x.Øa etc.
3. standardize variables: each quantifier gets its own variable
e.g. $x[P(x)] Ù Q(x) ß $z[P(z)] Ù Q(x) where z is a new variable
4. eliminate all existentials (discussed later)
5. move universals to the front using ("xa) Ù b ß "x(aÙ b)
where b does not use x
6. distribute Ú over Ù
7. collect terms
Get universally quantified conjunction of disjunction of literals
Answer predicate - A(x)
[~St(x), ~Happy(x), A(x)]
...
[A(bob)]
Skolem - names for individuals claimed to exist, called Skolem
Skolem preserve satisfiability, not equivalence so ExP(x) not equal P(a)!!
*MGU - most general unifier p70. / unification
- finding skolem variables theta given P(f(x), y, g(y)) and P(f(x), z, g(x)), answer is theta = {y/z, z/x} to get P(f(x), x, g(x))
***Note: important to get dependence of variables correct p65
AyExR(x,y) => AyR(f(y),y) so the best way to remember is to put brackets, it's better Ax (for all x) is inside the bracket because it's more flexible
vs. ExAyR(x,y) => AyR(a,y)
strategies:
- directional connectives (forward, backward)
- unit clauses
- set of support (always resolve with at least one clause that's the ancestor of ~q, just unifying with KB is useless)
- clause elimination, tautology (always true), pure clause (only one atom p in the formula)
horn clause = has at MOST one +ve literal (p80)
- as implications: (¬child ∨ ¬male ∨ boy)
- e.g. [¬p1, ¬p2, ..., ¬pn, q]
- e.g. [¬p1, ¬p2, ..., ¬pn] and also [ ] (all negative)
- p1 ∧ p2 ∧ ... ∧ pn ⇒ q (if p1 and p2 and ... and pn then q) or Note:
(¬p1 ∨ ¬p2 ∨ ... ∨ ¬pn ∨ q) or [(p1 ∧ p2 ∧ ... ∧ pn) ⊃ q]
SLD - (Selected literals) (linear form) (definite clauses)
sld derivation / resolution in Horn clauses - can also use a goal tree where the root is the goal and leaves are in the KB
back-chaining - depth first, left-right, back-chaining (strategy used in Prolog), can go to inf. loop
forward-chaining - mark atoms as solved
problem - can give inf. branch of resolvents in FOL
Standardize variables: each quantifier should use a different one
Ordering goals p94.
1. get ParentOf(sam,z): find child of Sam searching downwards
2. get ParentOf(z,sue): find parent of Sue searching upwards
3. get ParentOf(–,–): find parent relations searching in both directions
Search strategies are not equivalent
if more than 2 children per parent, (2) is best
Wednesday, January 6, 2010
IRIS OST/MV
[BIGBANG] Hallelujah MV [IRIS OST.]
http://www.youtube.com/watch?v=CvlgXwHUk58&NR=1
Shin Seung Hun IRIS OST Love Of Iris
http://www.youtube.com/watch?v=ctB_Ssuk64U&feature=related
Baek Ji Young - Don't Forget MV (IRIS OST)
http://www.youtube.com/watch?v=-Pq2LZhKFaA
http://www.youtube.com/watch?v=CvlgXwHUk58&NR=1
Shin Seung Hun IRIS OST Love Of Iris
http://www.youtube.com/watch?v=ctB_Ssuk64U&feature=related
Baek Ji Young - Don't Forget MV (IRIS OST)
http://www.youtube.com/watch?v=-Pq2LZhKFaA
ch 2 - ai

agent - anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators
percepts - location and contents, (room A, dirty)
rational agent - not omniscient (doesn't have everything in knowledge base, eg weather prediction) and not perfect (can be wrong, given limited information, i think the left turn is the right one ...)
peas - performance measure (quantifiable - accuracy, scores), environment, actuators, sensors, eg. taxi driver
***environment types -
* fully observable (chess, see everything) vs partially observable (taxi driving, can't see past buildings)
* deterministic (yes/no eg chess, move or not) vs stochastic (uncertainty, eg. driving, person might suddenly jump out of nowhere, traffic lights suddenly change)
* episodic (episodes, independent states, eg. part picking robot, image-analysis, only a few of these ...) vs sequential (eg. crossword, once you fill horizontal, the intersection is restricted with the letter.)
* static (you can take as much time as you like, there's no concept of time, eg. crossword, chess with no clock) vs dynamic (there are threads, eg. chess with clock, taxi driving - many things happen, thread for traffic light, thread for other car agents, thread for people crossing, etc.), vs semidynamic time,
* discrete(vs continuous) actions,
* single agent(vs multi)
- see slide 13 for example table
agent types (increasing generality)
1. simple reflex agents - condition-action (if statements) rules, very simple, state-less eg. vacuum with no memory, robot picking???, image analysis???
2. reflex agents with state / model based - knows the world, keeps states eg. chess / crossword??
3. goal-based agents - has reasoning (eg. red light, car in front stops, i should stop, i should slam on brakes), has a goal (replaces simple condition-action), eg. taxi driving
4. utility-based agents - maps state to degree of happiness to evaluate current state, how fast, how efficient, etc. eg. taxi driving, drive to destination the safest way
all these can be turned to learning agents - learning / feedback / critic
Classifying the environment
• Static / Dynamic
Previous problem was static: no attention to changes in environment
• Deterministic / Stochastic
Previous problem was deterministic: no new percepts
were necessary, we can predict the future perfectly
• Observable / Partially Observable / Unobservable
Previous problem was observable: it knew the initial state, &c
• Discrete / continuous
Previous problem was discrete: we can enumerate all possibilities
Tuesday, January 5, 2010
Monday, January 4, 2010
day 1 - intro to ai

Artificial intelligence : a modern approach / Stuart J. Russell and Peter Norvig ; contributing writ Russell, Stuart J. (Stuart Jonathan) -- Q 335 R86 2003 c.3
http://aima.cs.berkeley.edu/
intelligent agent - receive percepts from the environment and perform actions, implements a function that maps percept sequences to actions.
ai - think / act like humans or think/act rationally
intelligent systems - best possible action in a situation, systems that can decide what to do and then do it
***rational system - system that does the 'right thing', given what it knows,
disciplines
- natural language processing (talk), knowledge representation (store), automated reasoning (new), machine learning (adapt instead of duplicate, eg. airplane flying)
think humanly - cog sci
thinking rationally - logic, socrates, translate informal knowledge to formal terms using logical notation
*acting rationally - rational agent approach (tries to achieve the best expected outcome)
Internet - most important environment for intelligent agents
fields - vision, sonar, speech / writing recognition
state of the art;
- autonomous planning and scheduling - NASA's remote agent, Game playing - deep blue, autonomous control - ALVINN (auto car steering), diagnosis - medical expert systems, logistics planning, robots for microsurgery, language understanding and problem solving - solving crossword puzzles, writing poetry, giving advice, translation
agent - anything that perceives the environment through sensors and act on it through actuators
Sunday, January 3, 2010
Yuna Ito
Trust You - Yuna Ito (Full Song)
http://www.youtube.com/watch?v=wEt-JKw37NE
Pure Eyes - Rinoa & Squall - Yuna Ito
http://www.youtube.com/watch?v=rWxhskxQHoA
http://www.youtube.com/watch?v=wEt-JKw37NE
Pure Eyes - Rinoa & Squall - Yuna Ito
http://www.youtube.com/watch?v=rWxhskxQHoA
Places to visit
http://en.wikipedia.org/wiki/Akita_Prefecture
Mentioned "Akita" in the Korean Drama "IRIS". nice romantic spot during winter, nice outdoor onsen too!
http://en.wikipedia.org/wiki/Sitka,_Alaska
Nice bay side city of Alaska, mentioned in the movie "The Proposal (2009)", Sandra Bullock, funny movie ...
The Blind Side (2009) drama movie by Sandra Bullock is also nice, about a black football player who was adopted into a loving family who later enters the U-Miss (university of Mississippi).
How do you spell Mississippi with one eye? Close one of your eyes and spell it!
Mentioned "Akita" in the Korean Drama "IRIS". nice romantic spot during winter, nice outdoor onsen too!
http://en.wikipedia.org/wiki/Sitka,_Alaska
Nice bay side city of Alaska, mentioned in the movie "The Proposal (2009)", Sandra Bullock, funny movie ...
The Blind Side (2009) drama movie by Sandra Bullock is also nice, about a black football player who was adopted into a loving family who later enters the U-Miss (university of Mississippi).
How do you spell Mississippi with one eye? Close one of your eyes and spell it!
Saturday, January 2, 2010
printing with Canon Pixma MP560 in Ubuntu
Happy New Year - 2010
http://ubuntuforums.org/showthread.php?t=1264928
Re: printing with Canon Pixma MP560
If you check the Canon Asian site, they have drivers available (although the MP560 is the MP568 on the site; once you get to the driver page it states "MP560").
Actually, here:
http://support-asia.canon-asia.com/P/search?model=PIXMA+MP568&menu=download&filter=0&tagname=ca_os&ca_os=Linux
http://software.canon-europe.com/products/0010756.asp
Look for:
MP560 series IJ Printer Driver Ver. 3.20 for Linux (debian ...
and download the file.
Use Archive manager to extract the file and then look inside the directory it created. There should be a "packages" directory with 2 .deb files.
You can use dpkg to install the files (install the common file first) and if you're on a 64-bit system use the force option to make it work (that's why I had to use dpkg in the first place).
So you issue (it's important to install ia32-libs in amd64 systems prior to installation):
$ sudo apt-get install ia32-libs
$ sudo apt-get install libcupsys2$ sudo dpkg -i --force-architecture cnijfilter-common_3.20-1_i386.deb
$ sudo dpkg -i --force-architecture cnijfilter-mp560series_3.20-1_i386.deb
You can also modify install.sh to add sudo dpkg --force-architecture and run install.sh instead.
Gens
http://ubuntuforums.org/showthread.php?t=290008
http://127.0.0.1:631/
http://127.0.0.1:631/admin/log/error_log
/var/log/cups/error_log
$ lpinfo -v
$ sudo /etc/init.d/cups restart
$ vi /usr/share/ppd/canonmp560.ppd
https://sourceforge.net/projects/cups-bjnp/
http://ubuntuforums.org/showthread.php?t=1323409
PIXMA 560 = 620?
Device URI: cnijnet:/00-1E-8F-56-4A-C3
Make and Model: Canon MP560 series Ver.3.20
http://longair.net/blog/2010/06/06/the-canon-pixma-mp560-on-ubuntu/
http://ubuntuforums.org/showthread.php?t=1264928
Re: printing with Canon Pixma MP560
If you check the Canon Asian site, they have drivers available (although the MP560 is the MP568 on the site; once you get to the driver page it states "MP560").
Actually, here:
http://support-asia.canon-asia.com/P/search?model=PIXMA+MP568&menu=download&filter=0&tagname=ca_os&ca_os=Linux
http://software.canon-europe.com/products/0010756.asp
Look for:
MP560 series IJ Printer Driver Ver. 3.20 for Linux (debian ...
and download the file.
Use Archive manager to extract the file and then look inside the directory it created. There should be a "packages" directory with 2 .deb files.
You can use dpkg to install the files (install the common file first) and if you're on a 64-bit system use the force option to make it work (that's why I had to use dpkg in the first place).
So you issue (it's important to install ia32-libs in amd64 systems prior to installation):
$ sudo apt-get install ia32-libs
$ sudo apt-get install libcupsys2$ sudo dpkg -i --force-architecture cnijfilter-common_3.20-1_i386.deb
$ sudo dpkg -i --force-architecture cnijfilter-mp560series_3.20-1_i386.deb
You can also modify install.sh to add sudo dpkg --force-architecture and run install.sh instead.
Gens
http://ubuntuforums.org/showthread.php?t=290008
http://127.0.0.1:631/
http://127.0.0.1:631/admin/log/error_log
/var/log/cups/error_log
$ lpinfo -v
$ sudo /etc/init.d/cups restart
$ vi /usr/share/ppd/canonmp560.ppd
https://sourceforge.net/projects/cups-bjnp/
http://ubuntuforums.org/showthread.php?t=1323409
PIXMA 560 = 620?
Device URI: cnijnet:/00-1E-8F-56-4A-C3
Make and Model: Canon MP560 series Ver.3.20
http://longair.net/blog/2010/06/06/the-canon-pixma-mp560-on-ubuntu/
Subscribe to:
Comments (Atom)